spring.config.location启动的参数不互补可以使用spring.config.additional-location
星期六, 2021-11-27 | Author: Lee | JAVA-and-J2EE, linux | 没有评论 1,664 views

0.先说下springboot版本为2.5.7,location的会优先使用不再使用打包文件中的配置文件
详情见官方文档:https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#features.external-config.files
解决办法是:
java -jar -Dspring.config.location=/apps/config/app.properties /app/serverless/app.jar & ###替换一下即可 java -jar -Dspring.config.additional-location=/apps/config/app.properties /app/serverless/app.jar & |
1.起因需要给应用加上build time和version对应的版本号
这些参数可以在mvn的时候直接生成出来,但是在配置文件中将无法配置
先把这个做下记录
2.在pom.xml文件的properties中添加如下内容
<properties> <maven.build.timestamp.format>yyyy-MM-dd HH:mm:ss</maven.build.timestamp.format> <!--maven.build.timestamp保存了maven编译时间戳--> <timestamp>${maven.build.timestamp}</timestamp> </properties> ### 在pom.xml的build中添加如下内容,使properties能取到pom.xml中的数据 <resources> <resource> <directory>src/main/resources/</directory> <filtering>true</filtering> </resource> </resources> |
3.在springboot的配置文件中新增
app.name=pomelo app.build_time=@timestamp@ app.version=@project.version@ |
4.在spring 应用中使用即可获取打包时间及版本代码如下:
› 继续阅读
ThreadPoolExecutor的详解及自定义阻塞提交的ThreadLocalExcutor实例
星期二, 2021-11-02 | Author: Lee | JAVA-and-J2EE | 没有评论 2,364 views
ThreadPoolExecutor可以实现线程池的创建。ThreadPoolExecutor相关类图如下:
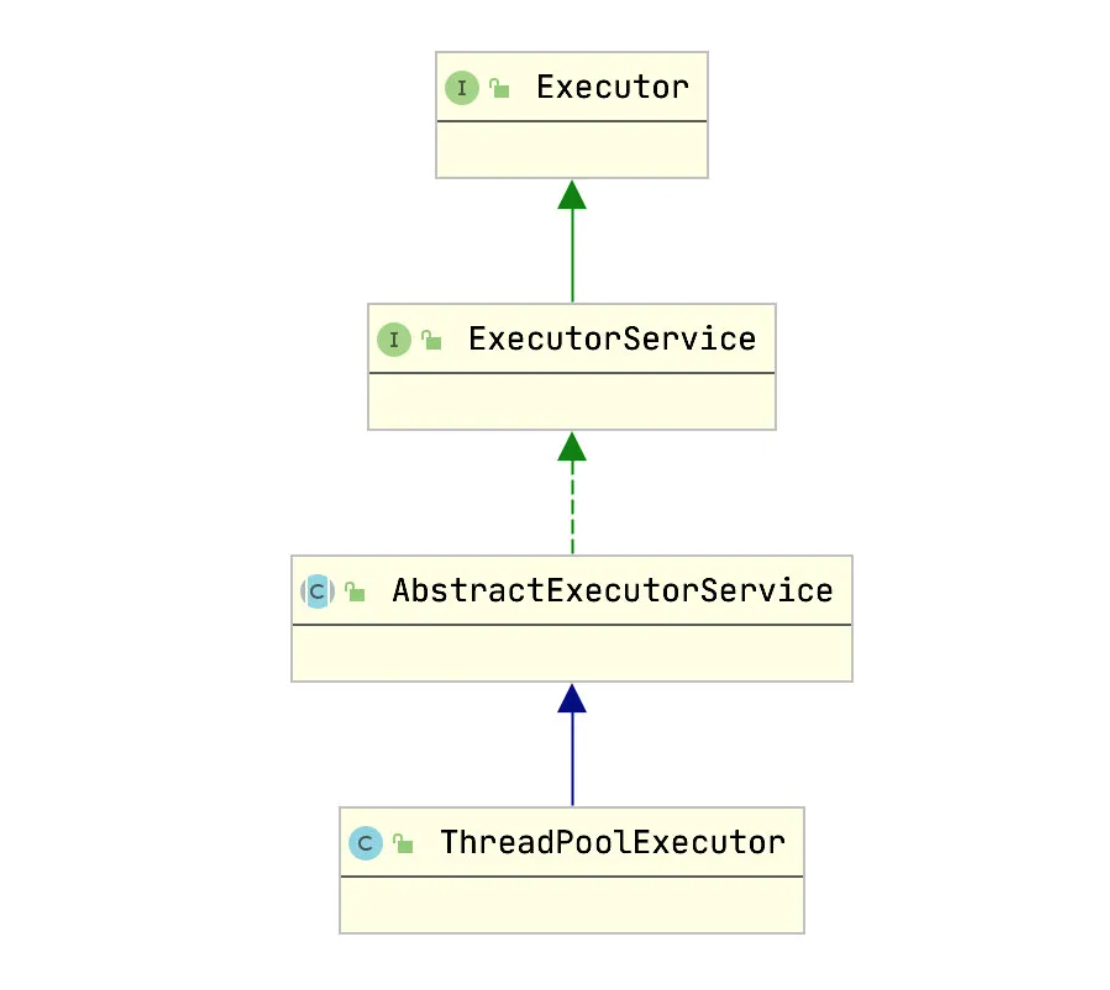
类图
从类图可以看出,ThreadPoolExecutor最终实现了Executor接口,是线程池创建的真正实现者。
Executor两级调度模型
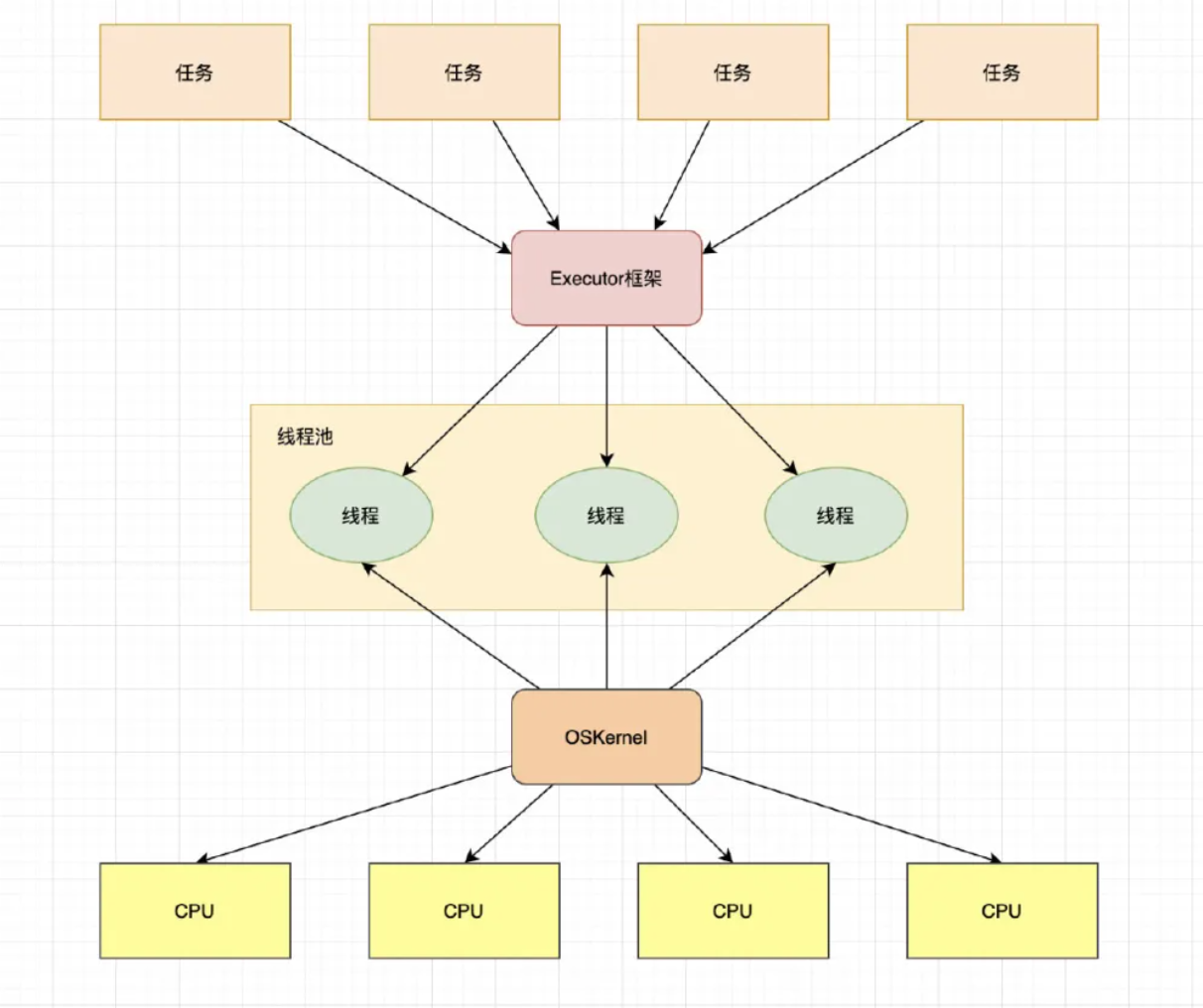
Executor模型
在HotSpot虚拟机中,Java中的线程将会被一一映射为操作系统的线程。在Java虚拟机层面,用户将多个任务提交给Executor框架,Executor负责分配线程执行它们;在操作系统层面,操作系统再将这些线程分配给处理器执行。
ThreadPoolExecutor的三个角色
任务
ThreadPoolExecutor接受两种类型的任务:Callable和Runnable。
Callable:该类任务有返回结果,可以抛出异常。通过submit方法提交,返回Future对象。通过get获取执行结果。
Runnable:该类任务只执行,无法获取返回结果,在执行过程中无法抛异常。通过execute或submit方法提交。
任务执行器
Executor框架最核心的接口是Executor,它表示任务的执行器。
通过上面类图可以看出,Executor的子接口为ExecutorService。再往底层有两大实现类:ThreadPoolExecutor和ScheduledThreadPoolExecutor(集成自ThreadPoolExecutor)。
执行结果
Future接口表示异步的执行结果,它的实现类为FutureTask。
三个角色之间的处理逻辑图如下:
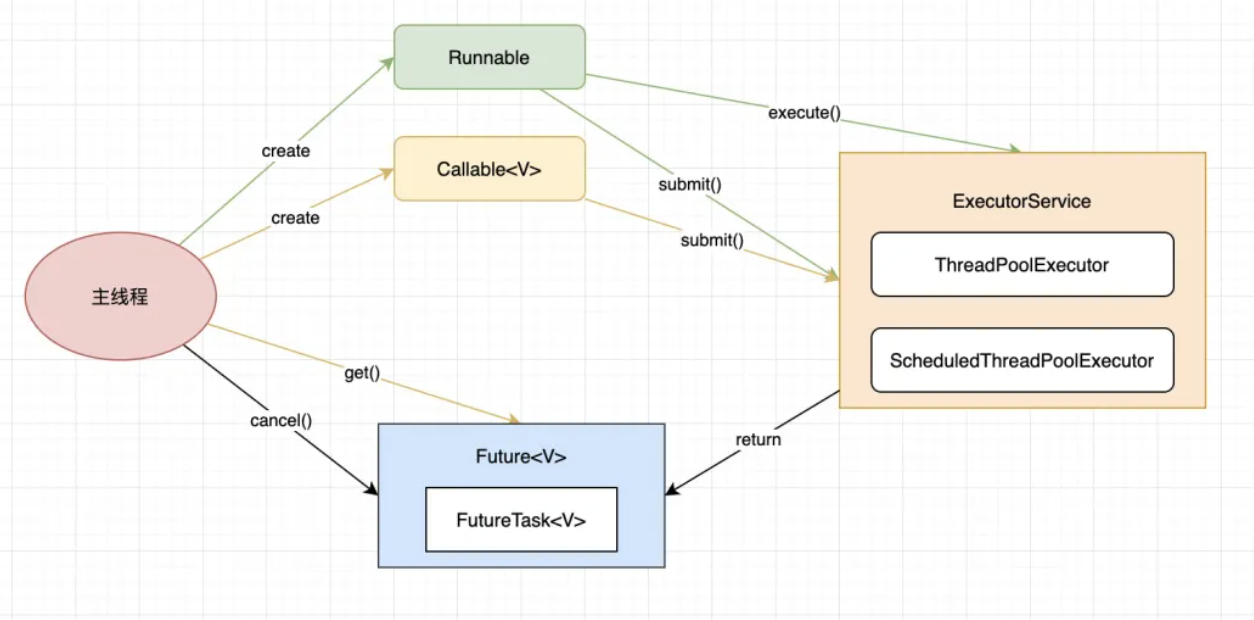
FutureTask逻辑
线程池处理流程
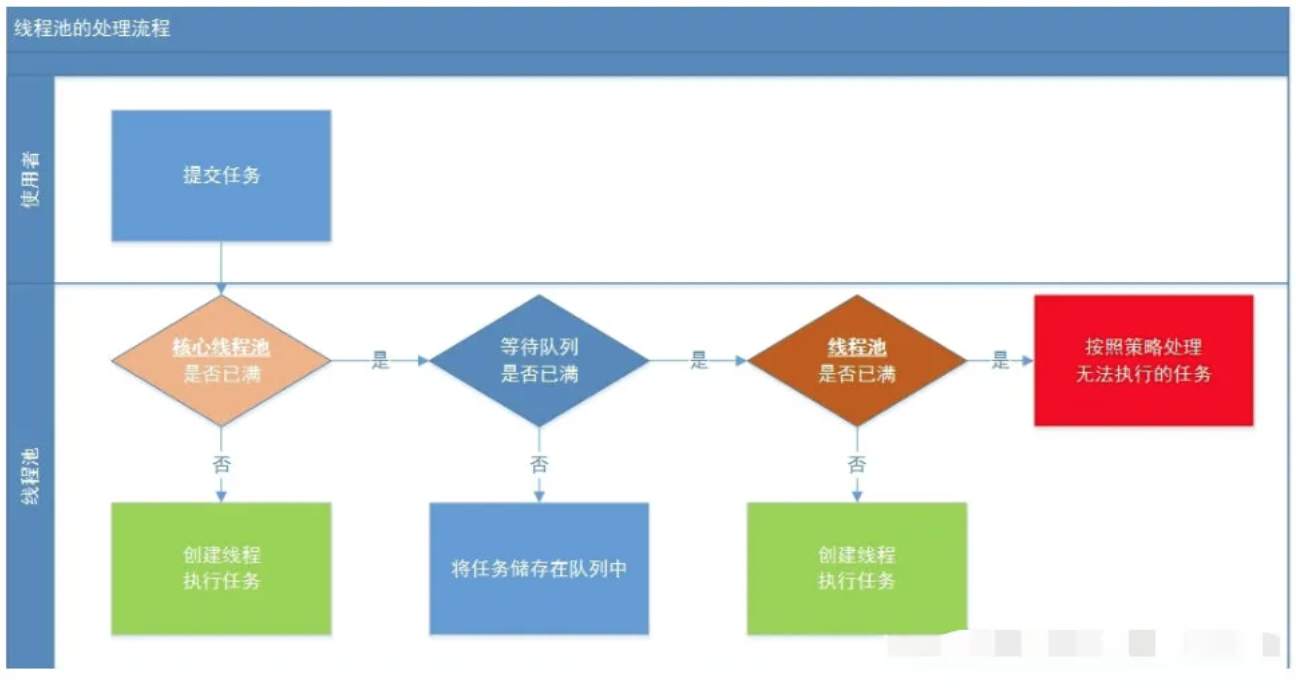
线程池处理流程
一个线程从被提交(submit)到执行共经历以下流程:
线程池判断核心线程池里是的线程是否都在执行任务,如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下一个流程;
线程池判断工作队列是否已满。如果工作队列没有满,则将新提交的任务储存在这个工作队列里。如果工作队列满了,则进入下一个流程;
线程池判断其内部线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已满了,则交给饱和策略来处理这个任务。
› 继续阅读
mac下的VirtualBox安装deepin自定义硬盘大小
星期三, 2021-10-27 | Author: Lee | computer, JAVA-and-J2EE, linux | 没有评论 1,276 views
mac下的VirtualBox安装deepin自定义硬盘大小
遇到的一些问题记录下解决过程
0.mac下安装VirtualBox遇到的无法启动问题(6.1.28)
系统偏好设置–》安全性及隐私
通用项目–》运行从以下地址下载的APP 开启任何来源 或者 APPstore和认可的开发者,详情里把 Oracle勾选上去
隐私项目–》辅助功能、完全磁盘访问权限、文件和文件夹 把VirtualBox的完全访问权限加上,其他自选加入不影响
1.下载deepin-desktop-community-20.2.4-amd64.iso文件,初始化硬盘30G大小
遇到全盘安装至少要64G否则无法安装,这里选左侧自定义安装
创建主分区,根目录下,选自动挂载,把30G的硬盘大小拖到最后,貌似至少需要19G。
2.进入不算太漫长的安装等待,一般会在5%的地方等待好久,慢慢等就好了,一般10来分钟即完成安装.
3.安装完成界面很小,不会跟随屏幕自动变大,要安装增强扩展,通过标题栏,一般会报错,找不到对应的iso挂载文件
这里可以看下cd里有没有挂载到VBoxGuestAdditions.iso,没有挂载的话,在cd驱动里选上即可
解决方法:手工挂载执行,找得到文件直接执行即可.
sudo su cd /media mkdir cdrom mount /dev/cdrom /media/cdrom cd cdrom sh VBoxLinuxAdditions.run |
Presto进程管理实现监控及自动重启
星期四, 2021-10-21 | Author: Lee | JAVA-and-J2EE, 大数据 | 没有评论 1,836 views
具体搭建就不说了可以参考官方文档
https://prestodb.io/docs/current/
其他查询接口也列下:
默认UI是:根据更改的端口调整
http://xxx:8080
获取集群状态 接口:
http://xxx/v1/cluster
获取NODE信息:接口:
http://xxx/v1/node
访问/v1/info/state, 直接从worker处获取worker的状态
取各节点的版本详情 获取节点信息的接口:
http://xxx/v1/service
具体监控信息如下:
› 继续阅读
mac下因为Apple无法检查其是否包含恶意软件的解决方法
星期二, 2021-09-21 | Author: Lee | computer | 没有评论 2,561 views
好久不安装其他软件了,今天下载了个发现无法打开,找了下解决之法:
macos关于打开软件出现“无法打开“指定软件,因为Apple无法检查其是否包含恶意软件,的问题解决;
首先打开terminal 命令行工具
然后输入命令:
sudo spctl --master-disable |
最后输入用户密码,
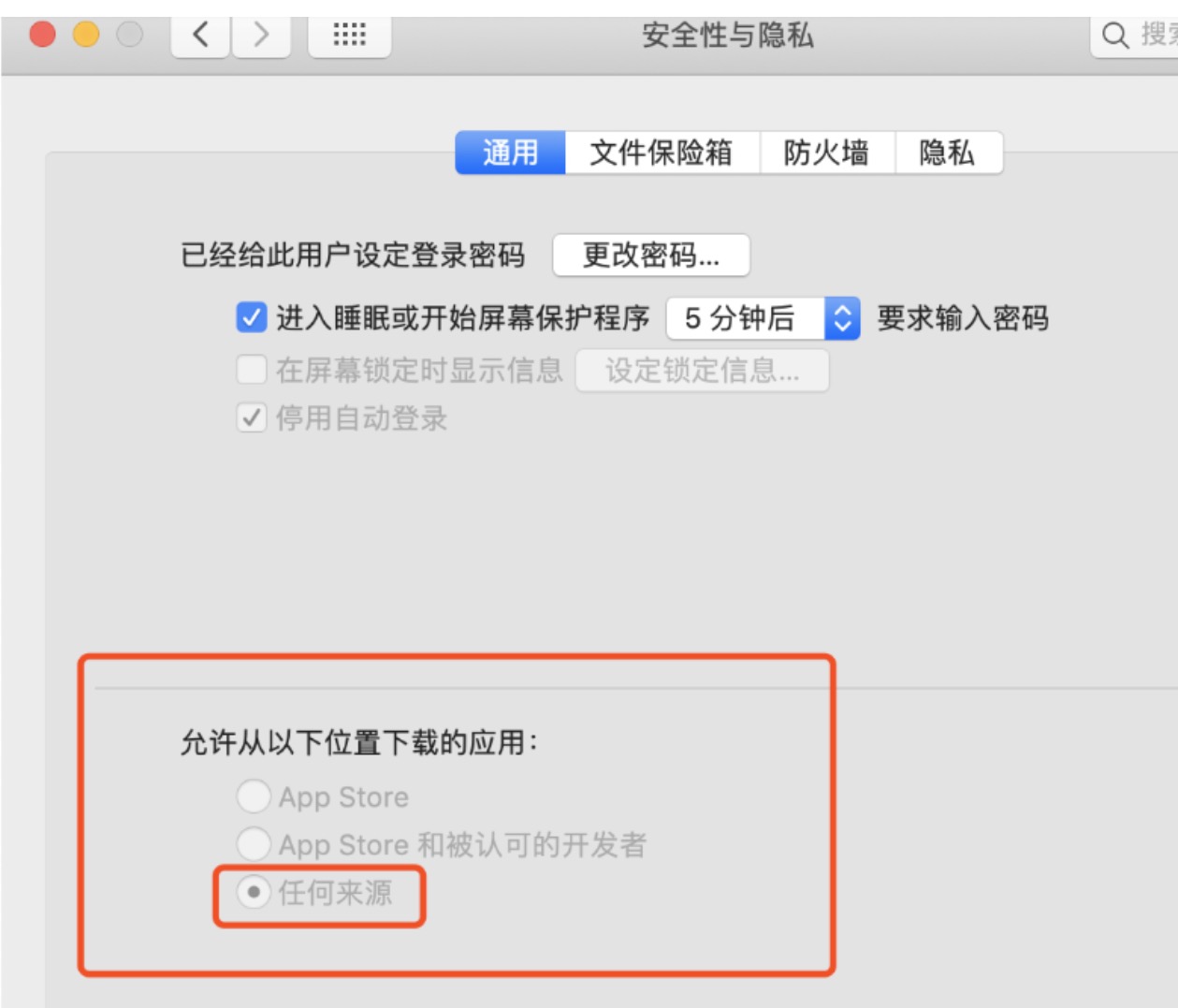
再打开 系统偏好设置–》安全性与隐私–》通用 –》运行从以下位置下载app–》开通 任何来源 –》仍然打开即可
如图所示:
eclipse2021-06版本使用lombok
星期五, 2021-08-13 | Author: Lee | JAVA-and-J2EE | 没有评论 2,805 views
Eclipse IDE for Enterprise Java and Web Developers (includes Incubating components)
Version: 2021-06 (4.20.0)
Build id: 20210612-2011
(c) Copyright Eclipse contributors and others 2000, 2021. All rights reserved. Eclipse and the Eclipse logo are trademarks of the Eclipse Foundation, Inc., https://www.eclipse.org/. The Eclipse logo cannot be altered without Eclipses permission. Eclipse logos are provided for use under the Eclipse logo and trademark guidelines, https://www.eclipse.org/logotm/. Oracle and Java are trademarks or registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
This product includes software developed by other open source projects including the Apache Software Foundation, https://www.apache.org/.
Lombok v1.18.20 “Envious Ferret” is installed. https://projectlombok.org/
上面是安装完成的版本信息
1.Lombok v1.18.20 下载 当前最新版本 https://projectlombok.org/
2. java -jar lombok.jar
3.安装完毕检查eclipse.ini下配置(需要自行添加–illegal-access=permit)使用jdk16出现的问题
-javaagent:/Applications/Eclipse.app/Contents/Eclipse/lombok.jar --illegal-access=permit |
4.重启eclipse可以正常使用
centos7通配ssl域名使用snap的certbot版本的lets-encrypt记录
星期日, 2021-07-25 | Author: Lee | computer, linux | 没有评论 10,797 views
之前直接使用脚本的形式现在已经不支持了,需要使用snap的模式
1.安装snap
sudo yum install epel-release -y sudo yum install snapd sudo systemctl enable --now snapd.socket sudo ln -s /var/lib/snapd/snap /snap sudo snap install core sudo snap refresh core |
2.移除历史的版本certbot
sudo yum remove certbot |
3.Install Certbot
sudo snap install --classic certbot sudo ln -s /snap/bin/certbot /usr/bin/certbot |
Elasticsearch技术使用(ES): 索引别名Aliases问题
星期四, 2021-07-08 | Author: Lee | JAVA-and-J2EE, 大数据 | 没有评论 1,763 views
业务问题#
业务需求是不断变化迭代的,也许我们之前写的某个业务逻辑在下个版本就变化了,我们可能需要修改原来的设计,例如数据库可能需要添加一个字段或删减一个字段,而在搜索中也会发生这件事,即使你认为现在的索引设计已经很完美了,在生产环境中,还是有可能需要做一些修改的,需要添加映射字段或者需要修改字段类型等等。
数据库中我们可以直接修改原来的表设计语句,前提是需要做好数据迁移。但是在 Elasticsearch 中就没那么简单了。尽管可以增加新的类型到索引中,或者增加新的字段到类型中,但是不能添加新的分析器或者对现有的字段做改动。如果你那么做的话,结果就是那些已经被索引的数据就不正确,搜索也不能正常工作。针对这个问题必须重新建立索引。
别名定义#
重新建立索引的问题是必须更新应用中的索引名称,索引别名就是用来解决这个问题的!
假设我们有个学生的原始索引 student_index_v1,我们给它起个别名 student_index,程序中也是用别名 student_index 进行搜索,当我们的业务需求发生改变需要修改索引的时候,我们重新创建个索引 student_index_v2,同时将别名 student_index 指向新的索引 student_index_v2,同时将 student_index_v1 的数据迁移到新的 student_index_v2,这样我们就可以做到在零停机下从旧索引切换到新索引。
索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用,而且别名不能与索引同名。
别名带给我们极大的灵活性,允许我们做下面这些:
在运行的集群中可以无缝的从一个索引切换到另一个索引。
给多个索引分组。
给索引的一个子集创建视图。
别名管理#
别名还可以映射到某个索引也可以映射到多个索引。别名还可以与筛选器关联,筛选器将在搜索和路由值时自动应用,别名不能与索引同名。
Elasticsearch 中有两种方式管理别名: _alias 用于单个操作, _aliases 用于执行多个原子级操作。
› 继续阅读
ssh连接好用的工具electerm或xshell
星期五, 2021-07-02 | Author: Lee | JAVA-and-J2EE, linux, mac, work-other | 没有评论 1,735 views
1.xshell基本上是window下常用的工具了,可以使用家庭版和学校版本免费
家庭或者学校版快速地址:https://www.netsarang.com/zh/free-for-home-school/
2.开源且使用起来还不错的electerm,支持linux, mac, win常用的三端
electerm is a terminal/ssh/sftp client(linux, mac, win) based on electron/ssh2/node-pty/xterm/antd/subx and many other libs.
Lambda架构和Kappa架构之常用的大数据处理架构
星期四, 2021-06-03 | Author: Lee | 大数据 | 没有评论 1,610 views
首先我们来看一个典型的互联网大数据平台的架构,如下图所示:
111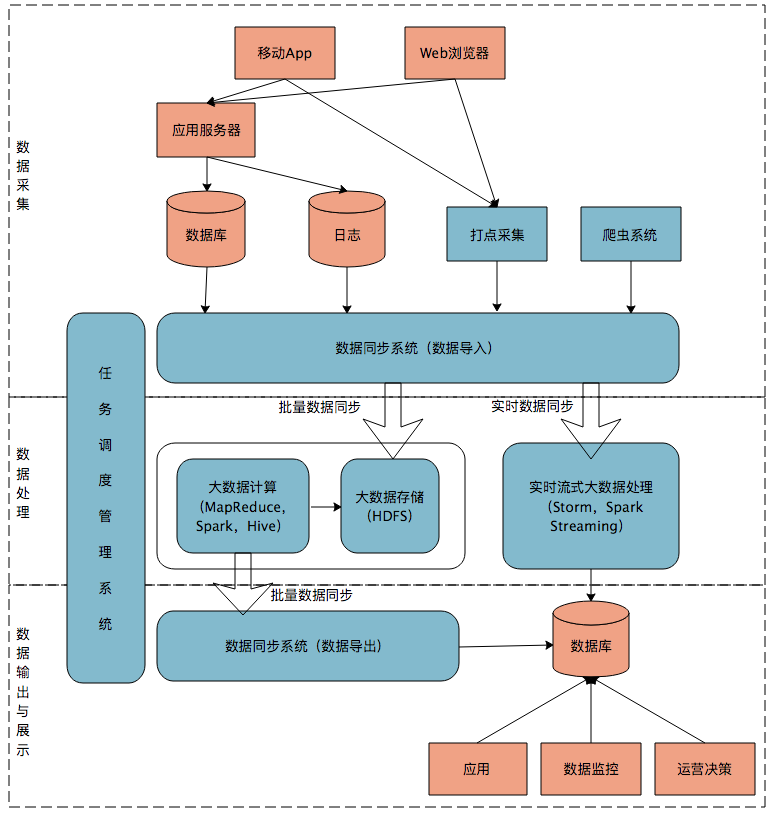
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS。
MapReduce、Hive、Spark 等进行的计算处理被称作是离线计算,HDFS 存储的数据被称为离线数据。在大数据系统上进行的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用 Storm、Spark Steaming 等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
数据输出与展示
大数据计算产生的数据还是写入到 HDFS 中,但应用程序不可能到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用 Sqoop 之类的系统导出到数据库。

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (86)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (144)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (7)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)