密码保护:人生七件套,「早读冥写跑复记」
星期日, 七月 27th, 2025 | Uncategorized | 要查看留言请输入您的密码。
114之前及115之后ChromeDriver 下载
星期日, 四月 27th, 2025 | computer, linux | 没有评论
最新重新安装个了linux下的chrome用来测试页面等,下载的是最新稳定版
想找下对应的驱动,发现变动还蛮大,记录下,方便后续查找
ChromeDriver下载页面(114之前ChromeDriver驱动版本)
淘宝镜像:CNPM Binaries Mirror
官方镜像:https://sites.google.com/a/chromium.org/chromedriver/downloads
ChromeDriver下载页面(115以后ChromeDriver驱动版本)
官网:Chrome for Testing availability
国内镜像:CNPM Binaries Mirror
amis展示内容新增可以复制功能
星期四, 八月 22nd, 2024 | 低代码 | 没有评论
默认 只要扩展JSON的属性 即可
{"copyable": true} |
如果要复制的值是有取其他变量,则不再可用,可以使用:
{
"copyable": {
"content": "${info|raw}"
}
} |
更多可以翻阅 amis对应文档
chrome召唤小恐龙游戏
星期日, 十二月 3rd, 2023 | computer | 没有评论
谷歌浏览器彩蛋:小恐龙游戏
chrome恐龙小游戏怎么出来_如何玩chrome的小恐龙游戏
谷歌Chrome怎么调出小恐龙游戏_谷歌浏览器调出小恐龙
一种方式:
电脑断网,打开谷歌浏览器就会出现小恐龙游戏,按空格键开启游戏
第二种方法:
打开谷歌浏览器在,浏览器的地址栏里输入:chrome://dino/
即可召唤出小恐龙游戏,同样按空格开启游戏
配置eclipse支持jdk21及体验虚拟线程
星期四, 九月 21st, 2023 | JAVA-and-J2EE | 没有评论
jdk21支持了虚拟线程,又是长期版本,体验下感觉
当前为止还只有官方版本,其他AWS等还没有对应的JDK21版本
下载地址:
openjdk 21
https://jdk.java.net/21/
oracle jdk 21
https://www.oracle.com/java/technologies/downloads/#jdk21-windows
graalvm-community-jdk-21.0.0_windows-x64_bin.zip
https://github.com/graalvm/graalvm-ce-builds/releases
graalvm-jdk-21_windows-x64_bin.zip
https://www.oracle.com/java/technologies/downloads/#graalvmjava21
eclipse下载最新:
Eclipse IDE 2023-09 R Packages
https://www.eclipse.org/downloads/packages/
eclipse更新支持插件:
Java 21 Support for Eclipse 2023-09 (4.29)
You can also install this feature from the following p2 update site directly:
https://download.eclipse.org/eclipse/updates/4.29-P-builds/
在install soft里使用上面地址加载编译支持jdk21可选
配置jdk21和编译支持如图
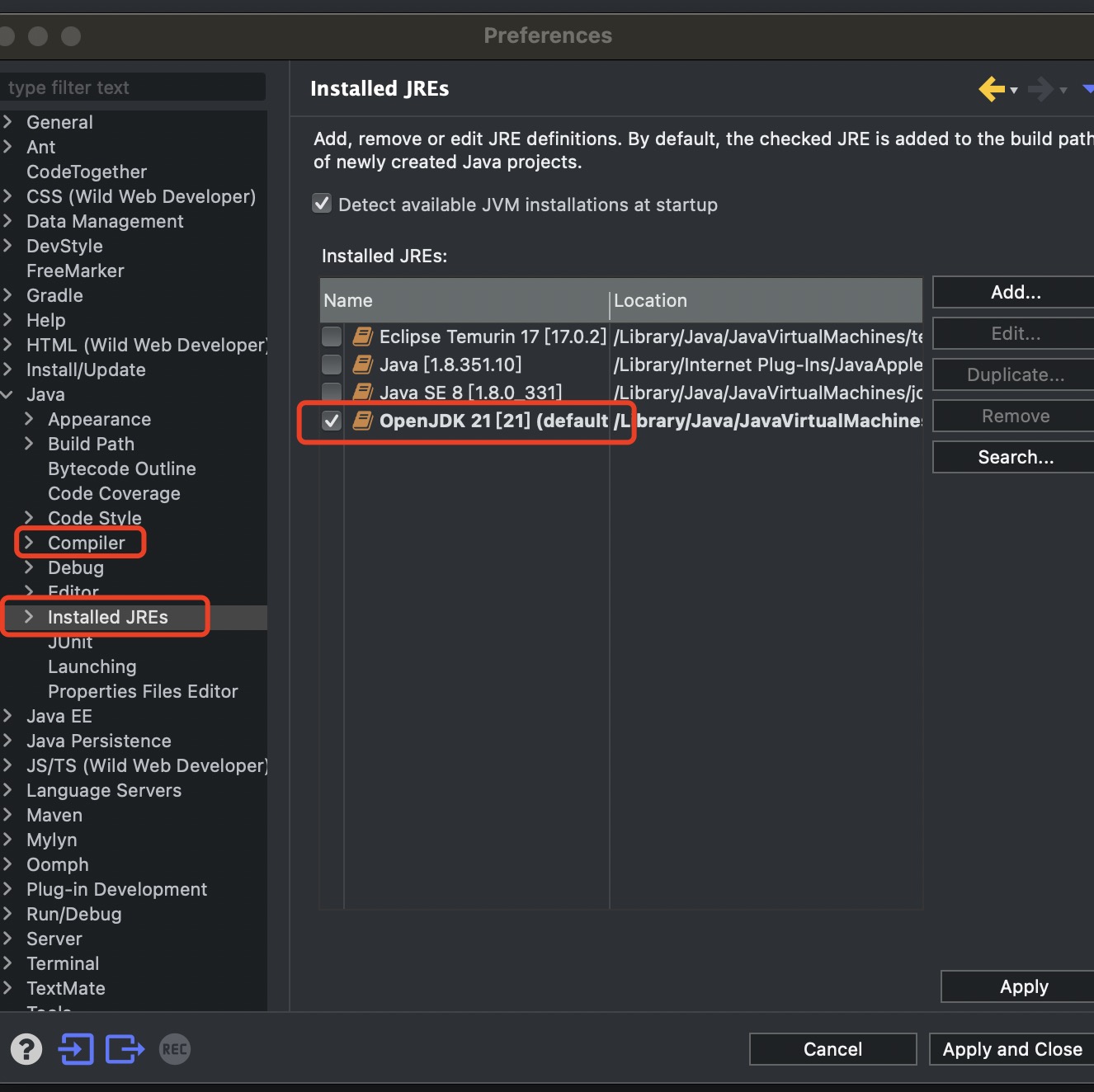
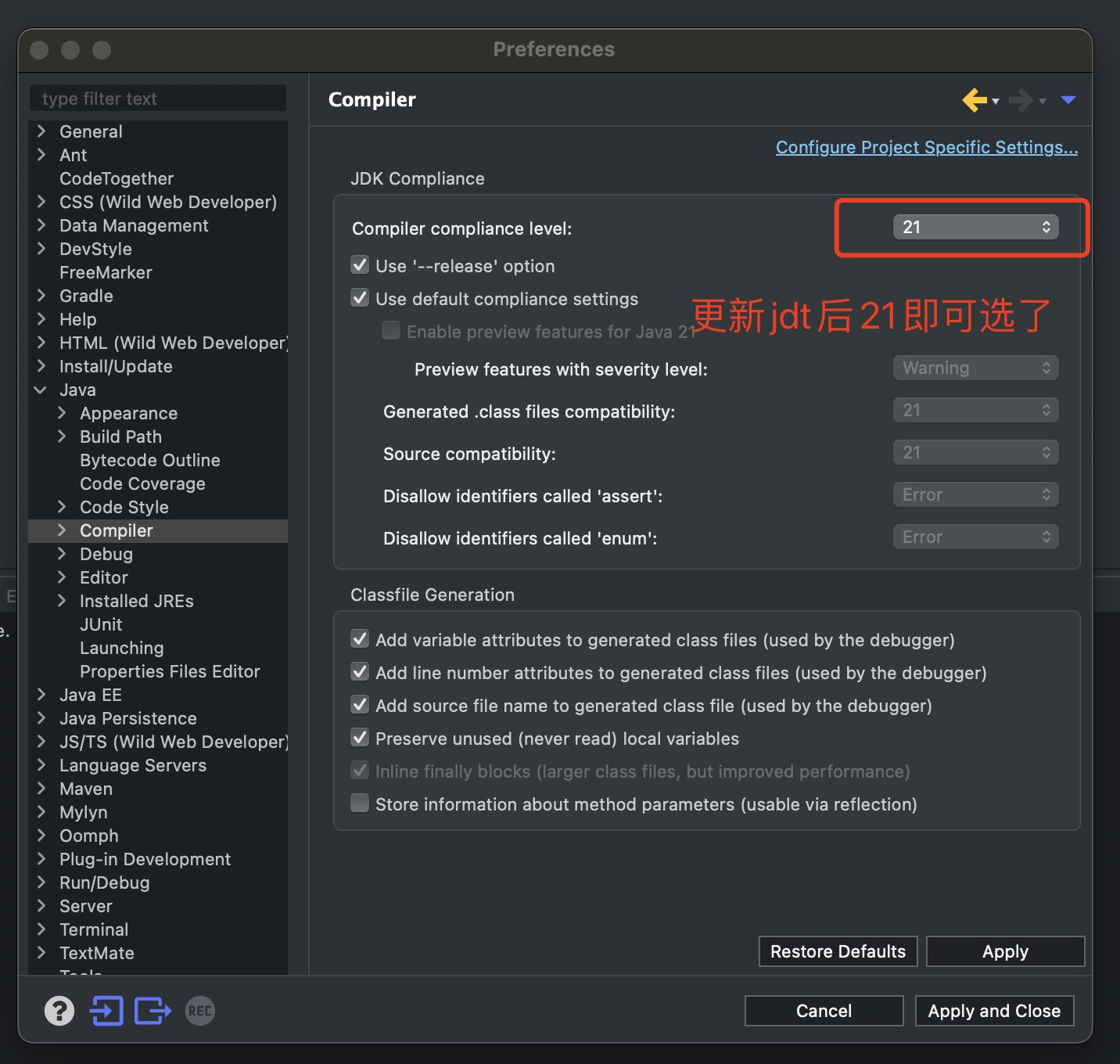
更新启动异步线程加载,以前使用5个异步线程,现在用虚拟线程替换,其他不用更改
代码片段:
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor(); @PostConstruct public void init() { executor.submit(() -> { xxx(); }); executor.submit(() -> { xxx2(); xxx3(); }); executor.submit(() -> { xx4(); xx5(); }); executor.submit(() -> { xxx6(); xxx7(); }); } |
启动 还比较流畅,应用使用了springboot3.1.3版本
使用Nginx流量代理https站点转发
星期五, 八月 18th, 2023 | computer, linux | 没有评论
网上找了一圈,终于找到一个可用的,配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
server
{
listen 443;
server_name proxypay.xx.com;
ssl on;
ssl_certificate /etc/nginx/1_proxypay.xx.com_bundle.crt;
ssl_certificate_key /etc/nginx/2_proxypay.xx.com.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
location / {
proxy_pass https://pay.xx.com/;
proxy_ssl_certificate /etc/nginx/1_pay.xx.com_bundle.crt;
proxy_ssl_certificate_key /etc/nginx/2_pay.xx.com.key;
}
} |
FreeMarker常用方式总结及问题解决
星期三, 八月 2nd, 2023 | JAVA-and-J2EE | 没有评论
概念
FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配 置文件,源代码等)的通用工具。 是一个Java类库。
FreeMarker 被设计用来生成 HTML Web 页面,特别是基于 MVC 模式的应用程序,将视图从业务逻辑中抽离处理, 业务中不再包括视图的展示,而是将视图交给 FreeMarker 来输出。虽然 FreeMarker 具有一些编程的能力,但通常 由 Java 程序准备要显示的数据,由 FreeMarker 生成页面。通过模板显示准备的数据(如图):
需要注意:
FreeMarker不是一个Web应用框架,而适合作为Web应用框架一个组
FreeMarker与容器无关,因为它并不知道HTTP或Servlet。FreeMarker同样可以应用于非Web应用程序环境
FreeMarker更适合作为Model2框架(如Struts)的视图组件,你也可以在模板中使用JSP标记库。
Freemarker环境搭建
${变量} 表达式
后端返回数据Model
request.setAttribute("msg","hello word"); |
页面使用 ${} 语法
<h1>${msg}</h1> |
渲染后显示
hello word |
freemarker数据类型
freemarker模板中的数据类型主要由如下几种:
布尔型:等价于 Java 的 Boolean 类型,不同的是不能直接输出,可转换为字符串输出
日期型:等价于 java 的 Date 类型,不同的是不能直接输出,需要转换成字符串再输出
数值型:等价于 java 中的 int,float,double 等数值类型 有三种显示形式:数值型(默认)、货币型、百分比型
字符型:等价于 java 中的字符串,有很多内置函数
sequence 类型:等价于 java 中的数组,list,set 等集合类型
hash 类型:等价于 java 中的 Map 类型
布尔型
数据
request.setAttribute("flag", true); |
获取
// 方式一 ${flag?c} // 方式二 ${flag?string} // 方式三 ${flag?string("yes","no")} |
这里用到的是freemarker的内置函数,如 ?c 和 ?string,前面说到了,布尔型的数据是不能直接输出的,需要对其进行转换,转换为字符串才能正常输出。所以 ?c 和 ?string都是把其它类型转换为字符串类型的内置函数。
› Continue reading
最长公共子串问题的java版计算
星期三, 五月 17th, 2023 | algorithm-learn, JAVA-and-J2EE, linux | 没有评论
1.最长公共子串问题
【题目】给定两个字符串str1和str2,返回两个字符串的最长公共子串。
【举例】str1="1AB2345CD",str2="12345EF",返回"2345"。
【要求】如果 str1 长度为 M,str2 长度为N,实现时间复杂度为 O(M×N),额外空间复杂度为 O(1)的方法。
【难度】3星
/** * * 1.最长公共子串问题 【题目】给定两个字符串str1和str2,返回两个字符串的最长公共子串。 * 【举例】str1="1AB2345CD",str2="12345EF",返回"2345"。 【要求】如果 str1 长度为 M,str2 长度为 * N,实现时间复杂度为 O(M×N),额外空间复杂度为 O(1)的方法。 【难度】3星 * * @author sara * */ public class MaxSubStr { public static void main(String[] args) { String str1="1AB2345CD",str2="12345EF"; String str = getMaxSub(str1,str2); System.out.println(str); } public static String getMaxSub(String s1, String s2) { String sStr = s1, mStr = s2; if (s1.length() > s2.length()) { sStr = s2; mStr = s1; } String str = ""; for (int i = 0; i < sStr.length(); i++) { for (int j = 1; j < sStr.length() - i; j++) { if (mStr.contains(sStr.substring(i, i + j)) && j > str.length()) { str = sStr.substring(i, i + j); } } } return str; } public static void getDp(char[] str1, char[] str2) { } } |
linux、centos等配置不输入密码切换sudo指令
星期二, 五月 16th, 2023 | JAVA-and-J2EE, linux | 没有评论
使用 pkexec 安全配置指定用户不输入密码切换sudo su指令
1.pkexec su可进入你的root
pkexec visudo 进入visudo命令
直接编辑修改
ctrl + x 保存退出
编辑的也是此文件,在对应的用户前面加上NOPASSWD即可
在/etc/sudoers文件
sa ALL=(ALL) NOPASSWD:ALL
2.小问题修复 为了能编辑/etc/sudoers 执行给了777权限
出现如下错误
sudo: /etc/sudoers is world writable
sudo: no valid sudoers sources found, quitting
sudo: unable to initialize policy plugin
修复此错误:
pkexec chmod 0440 /etc/sudoers |
JS Code block 代码块–URL
星期二, 四月 18th, 2023 | computer, 前端 | 没有评论
URL
获取window.URL 实例
获取url中的参数
删除url中参数
增加url中的参数
获取URL里domain
返回url的pathName
http协议转换为https
将dataURL转换为blob
blob2DataURL

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (86)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (144)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (7)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)