JS Code block 代码块–日期
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 698 views

日期
按类型格式化日期
设置几天后的日期
获取当前时间的n天后的时间戳
本周第一天
本周最后一天
本月第一天
本月最后一天
日期转时间戳
返回指定时间戳之间的时间间隔
星期转换,将数字转换成英文
月份转换,将数字转换成英文
是否为闰年
返回两个年份之间的闰年
› 继续阅读
JS Code block 代码块–图片
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 363 views
图片
图片下载
图片转成base64
canvas标签转换成img标签
Base64转Blob对象
创建一个canvas,并获取 CanvasRenderingContext2D
内容以文件形式下载下来
浏览器是否支持webP格式图片
› 继续阅读
JS Code block 代码块–regex 正则表达式
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 1,039 views
regex 正则表达式
是否由 26 个英文字母组成的字符串
是否由 26 个英文字母的大写组成的字符串
是否由 26 个英文字母的小写组成的字符串
是否为数字
是否为中文
是否为手机号
是否电子邮件
是否为座机号
是否为身份证
密码验证
邮政编码
是否为qq号
是否为金额
是否为Url
是否为ip
严格的身份证校验
移除标签
是否为 HTML 标签
检查是否为特殊字符
是否为有效的统一社会信用代码
是否为有效的A股代码
是否为有效的银行卡号
是否为有效的 base64格式
是否为有效的ed2k链接
是否为有效的IP v4
是否为有效的IP v6
是否为有效的md5格式(32位)
是否为有效的护照
是否为有效的子网掩码
› 继续阅读
JS Code block 代码块–数组(array)
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 346 views
数组(array)
判断一个元素是否在数组中
数组进行去重
数组合并
将类数组转换为数组
获取数组中最大值
获取数组中最小值
计算某值在数组中出现的次数
去除数组中假值元素
获取数组的最后一项
› 继续阅读
JS Code block 代码块–数字
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 634 views
数字
数字位数前面补0
角度转换为弧度
弧度转换为角度
生成随机数
阿拉伯数字翻译成中文的数字
将数字转换为大写金额
生成唯一值uuid
字节大小
千分数值格式
加法函数,用来得到精确的加法结果
除法函数,用来得到精确的除法结果
乘法函数,用来得到精确的乘法结果
减法函数,用来得到精确的减法结果
› 继续阅读
JS Code block 代码块–横向滚动翻页
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 682 views
横向滚动翻页
横向滚动插件,是一个有横向翻页按钮,同时翻页时有滚动效果的插件。在公司官网展示不是很多东西情况下会经常用到。
demo
可以在本地下载这个项目: https://github.com/PhilipsYuan/horizontal-roll-pagination, 然后在 本地跑下demo.html 文件
使用说明
你需要引入horizontal-roll-pagination.js, 引入之后会在全局window下有个属性HorizontalRollPagination,你可以new 它创建实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | let config = { // preDom: 前一页的按钮节点 -- 必须 preDom: document.getElementsByClassName('prev')[0], // nextDom: 后一页的按钮节点 -- 必须 nextDom: document.getElementsByClassName('next')[0], // box: 可视区域的节点 -- 必须 box: document.getElementsByClassName('box')[0], // scrollDom: 会被移动的节点 -- 必须 scrollDom: document.getElementsByClassName('scroll_list')[0], // parentDom: 展示项的父节点 -- 必须 parentDom: document.getElementsByTagName('ul')[0], // 是否循环 loop: true }; let horizontalRollPagination = new HorizontalRollPagination(config); horizontalRollPagination.init(); |
这个插件对dom节点需要一定要求。它的结构如下:
› 继续阅读
JS Code block 代码块–环境判断
星期一, 2023-04-17 | Author: Lee | computer, 前端 | 没有评论 688 views
环境判断
判断是否在微信环境
是否安卓环境
是否iphone环境
是否ios环境(包括iPhone和ipad)
是否safari环境
是否为windows系统
是否为mac系统(包含iphone手机)
是否是支付宝内核
是否是QQ浏览器内核
是否是UC浏览器内核
是否是微博内核
获取浏览器的类型
获取设备像素比
判断 iPhone X Series 机型,刘海屏
› 继续阅读
基于phantomjs的截图优化JS信息
星期三, 2023-04-05 | Author: Lee | computer, JAVA-and-J2EE, linux | 没有评论 581 views
phantomjs是比较老的一种模拟抓取及截图,这个是以前处理截图的一种优化js信息做个留档
以后应该是不用了
img.js和rasterize.js两个文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | var page = require('webpage').create(), system = require('system'), address, output, size;
if (system.args.length < 3 || system.args.length > 5) {
phantom.exit(1);
} else {
address = system.args[1];
output = system.args[2];
//定义宽高
/* page.viewportSize = {
width : 1024,
height : 768
};*/
page.open(address, function(status) {
var bb = page.evaluate(function() {
return document.getElementsByTagName('html')[0].getBoundingClientRect();
});
page.clipRect = {
top : bb.top,
left : bb.left,
width : bb.width,
height : bb.height
};
window.setTimeout(function() {
page.render(output);
page.close();
console.log('渲染成功...');
console.log(address);
phantom.exit();
}, 1000);
});
} |
SpringBoot应用的jar包重新打包
星期三, 2023-03-15 | Author: Lee | JAVA-and-J2EE | 没有评论 755 views
1.对应历史的运行中的jar包,需要更改下对应配置 或者其中的一个class文件可以直接使用命令重新打包
2.如下即可
unzip ../my-boot-app.jar vim BOOT-INF/classes/application-pro.properties jar uf ../my-boot-app.jar BOOT-INF/classes/application-pro.properties |
3.这样只更新对应的文件即可
美化Eclipse链式调用的代码格式化(Formatter)
星期二, 2022-10-18 | Author: Lee | JAVA-and-J2EE | 没有评论 1,394 views
eclipse下的链式调用格式化的时候挤成一行,看起来很难受.
需要调整 Eclipse 默认的代码格式化——在按下「Ctrl + Shift + F」后,编辑器能够自动将链式调用代码换行。怎么办呢?
在 Eclipse 中按照以下顺序打开代码格式化的配置项:
Windows → Preferences → Java → Code Style → Formatter
选择「New…」新建一个格式化的配置。
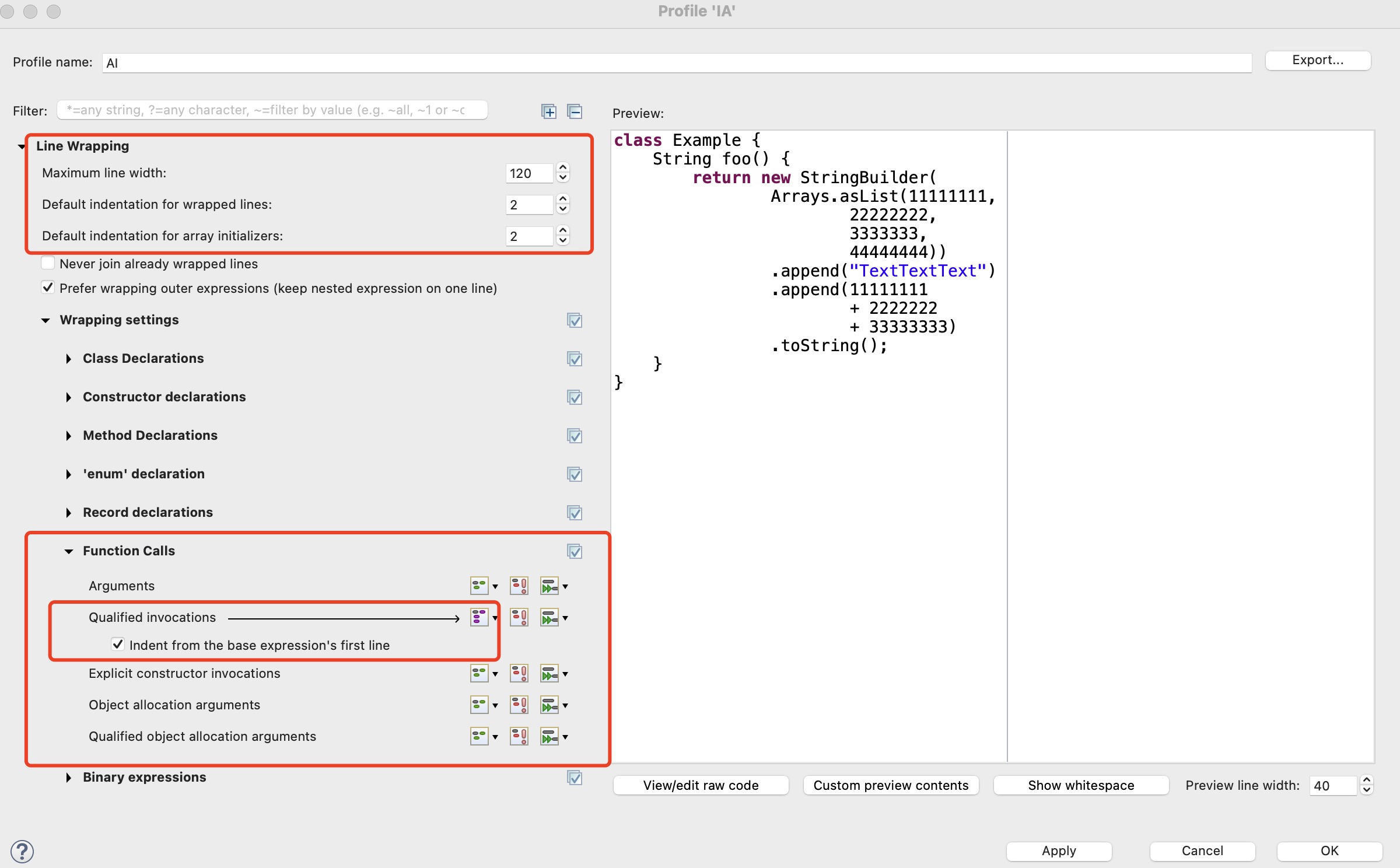
关键的配置项如下:
1、Maximum line width:120「一行最大宽度,120」(超过 120 就自动换行)
2、Function Calls → Qualified Invocations「方法调用 → xxxxx」
其中 line wrapping policy 「换行策略」选择:
wrap all elements, except first element if not necessary「第一个元素可以不换行,其他都换行」
并且勾选复选框 force split, even if line shorter than maximum line width「强制换行,即使该行没有达到最大换行的宽度」
这样设置后,Eclipse 就能够为链式调用的代码自动换行了。效果如下图。
不过,这样的换行效果仍然不够理想,如果换行策略优化为:
wrap all elements, except second element if not necessary「前两个元素可以不换行,其他都换行」
这样就更好了。

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (86)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (144)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (6)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)