大数据
日志中台不重不丢的实现架构及问题处理
星期三, 四月 20th, 2022 | JAVA-and-J2EE, 大数据 | 没有评论
可以参考实现自己公司的日志中台 来源:百度Geek说
导读:日志数据的生命周期包含日志采集、接入、传输、应用等各个环节。数据的稳定性对于公司报表建设、决策分析、转化策略效果都有至关重要的影响。全文旨在介绍百度日志中台当前的现状,公司内部应用推广情况。尤其在数据准确性的建设上,进行深入的探讨。数据产生到最终业务应用中各个环节的稳定性建设,包括:数据上报时效性优化、接入持久化的思考、数据流式计算过程中的不重不丢建设等。
一 简述
1.1 中台定位
日志中台是针对打点数据的一站式服务,实现打点数据的全生命周期管理,只需简单开发就能快捷完成日志数据采集、传输、管理以及查询分析等功能,适用于产品运营分析、研发性能分析、运维管理等业务场景,帮助APP端、服务端等客户探索数据、挖掘价值、预见未来。
1.2 接入情况
日志中台已覆盖了厂内大多数重点产品,其中包括:百度APP全打点、小程序、矩阵APP等,接入方面收益如下:
接入情况:几乎覆盖了厂内已有APP,小程序,创新孵化APP,以及厂外收购APP
服务规模:日志条数 几千亿 条/天,高峰QPS 几百万/秒,服务稳定性 99.9995 %
1.3 名词解释
客户端:指用户可以直接使用的软件系统,通常部署在用户手机或PC等终端设备上。例如百度APP、小程序等。
服务端:用于响应客户端发起的网络请求的服务,通常部署在云服务器上。
日志中台:此处特指端日志中台,包括端日志全生命周期的能力建设。包括打点SDK / 打点server/ 日志管理平台等核心组件。
打点SDK:负责打点日志的采集、封装、上报等功能。根据不同的日志生产端,分为APP端SDK、H5端SDK,根据场景区分为通用点位SDK、性能SDK、小程序SDK等,用户根据需求可以集成不同的SDK。
打点server:日志接收服务端,是日志中台服务端最核心的模块。
特征/模型服务:日志中台将需要进行策略模型计算的点位信息实时转发给下游<策略推荐中台>。特征/模型服务是<策略推荐中台>的入口模块。
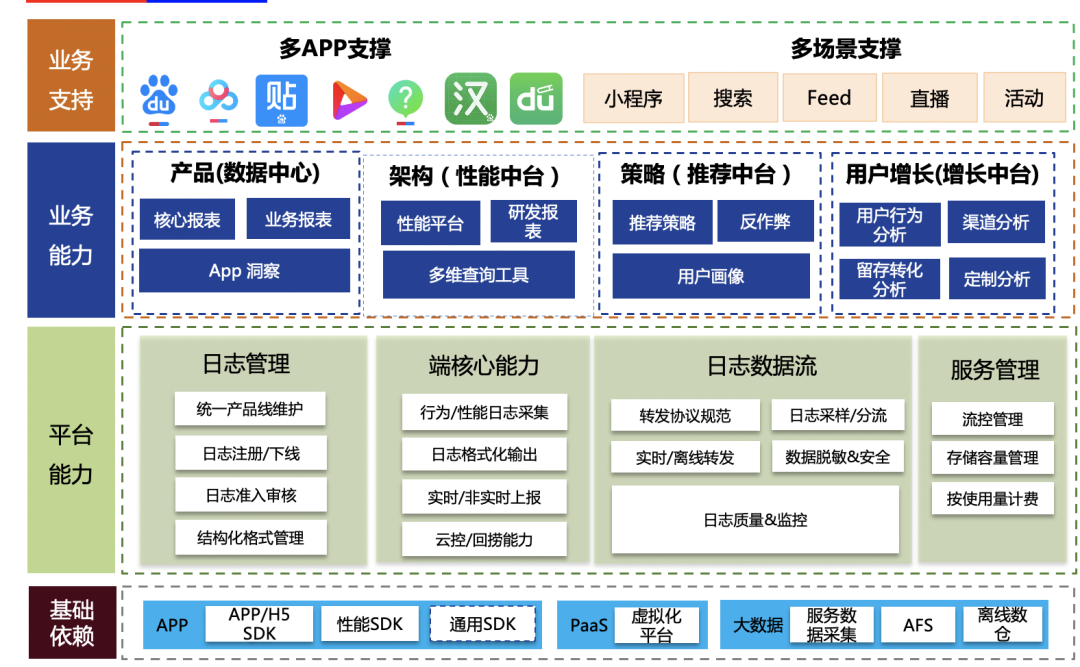
1.4 服务全景图
日志服务主要包括基础层、管理平台、业务数据应用、产品支撑几个层面。围绕着各个层级,在2021.6月,制定&发布了百度客户端日志上报规范。
基础层:支持了APP-SDK、JS-SDK,性能SDK、通用SDK,满足各类打点需求的快速接入场景。依托大数据基础服务,将打点数据分发至各个应用方。
平台层:管理平台支持数据元信息管理、维护,并控制打点生命全周期环节。在线层面支持数据的实时、离线转发、并依托合理的流量控制、监控保证服务稳定性在99.995%。
业务能力:日志打点数据输出至数据中心、性能平台、策略中台、增长中台等,有效助力产品决策分析、端质量监控、策略增长等领域。
业务支持:覆盖重点APP、新孵化矩阵APP,横向通用组件方面。
二、日志中台核心目标
如前文介绍,日志中台承载着百度内所有APP日志打点、站在数据生产的最前沿,在保证功能覆盖全、接入快速&灵活的基础上,面临的最重要核心挑战是数据的准确性。整个数据从产出、日志中台接入处理、下游应用,一切数据质量问题需要日志中台承载。而数据的准确性可以拆解为2部分:
不重:保证数据严格意义的不重复。需要防止系统层面的各种重试、架构异常恢复导致的数据重复问题;
不丢:保证数据严格意义的不丢失。需要防止系统层面的故障、代码层面bug等导致的数据丢失问题。
而做到系统层面的近乎100%的不重不丢,需要面临较多的难题。
2.1 日志中台架构
接入日志中台打点数据从端上生产至在线服务到最终(实时/离线)转发至下游,需要经过如下几个环节:
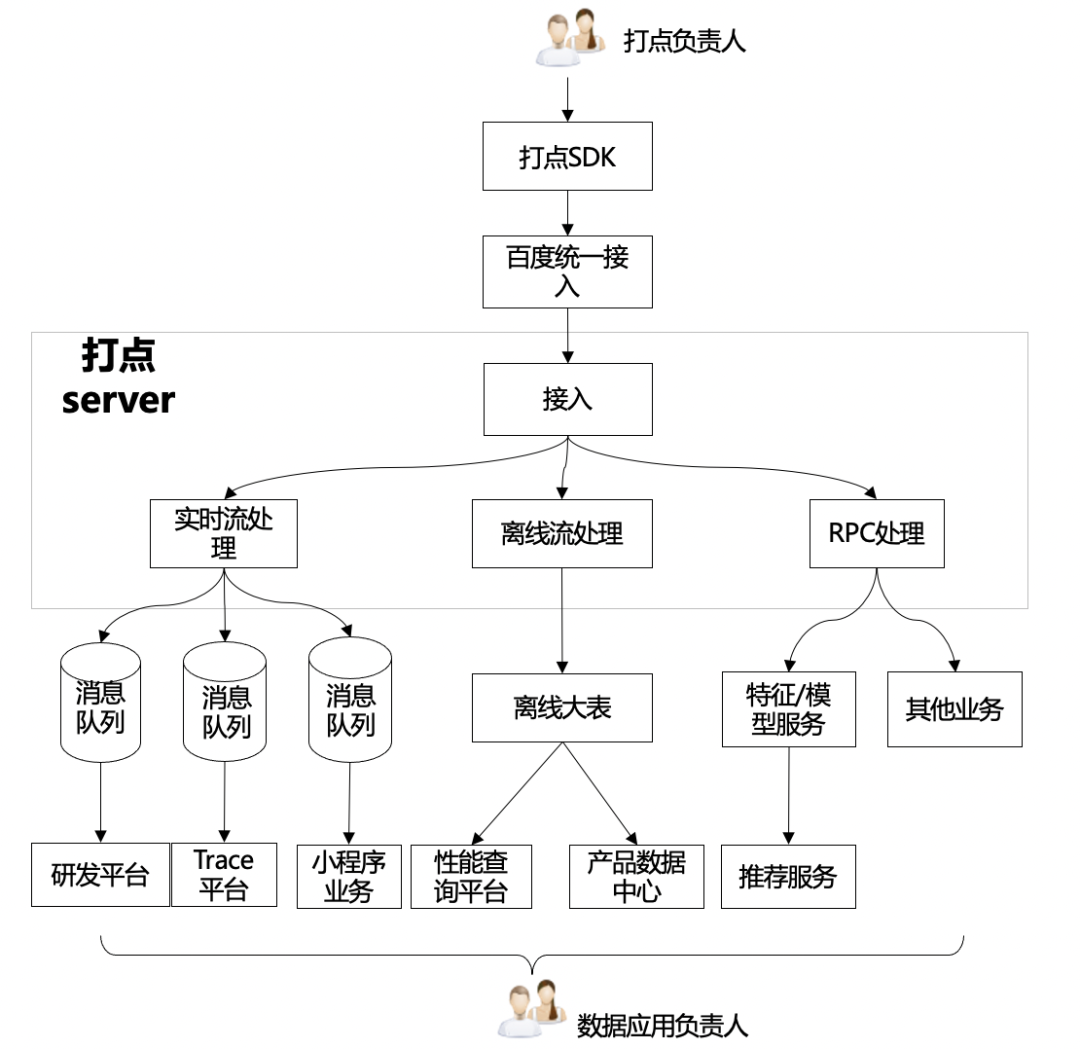
数据应用方式不同,有以下集中类型:
实时
准实时流(消息队列):供下游数据分析使用,特点:较高(min)时效性,需要严格意义的数据准确。典型应用:研发平台、trace平台;
纯实时流(RPC代理):供下游策略应用,特点:秒级时效性,允许一定程度的数据丢失。典型应用:推荐架构。
离线:离线大表,所有日志全集,特点:天级/小时级时效性,需要严格意义的数据准确。
其他:需要一定时效性和准确率
2.2 面临的问题
从上面日志中台架构来看,存在如下问题:
巨型模块:打点server承载了所有的数据处理逻辑,功能耦合严重:
功能多:接入&持久化、业务逻辑处理、各种类型转发(rpc、消息队列、pb落盘);
扇出多:有10+个业务扇出流,通过打点server转发。
直接对接消息队列:从业务视角看,存在发送消息队列消息丢失风险,且无法满足业务不重不丢要求。
业务无等级划分:
核心业务与非核心业务架构部署耦合
相互迭代、相互影响
三、不重不丢实现
3.1 数据不丢的理论基础
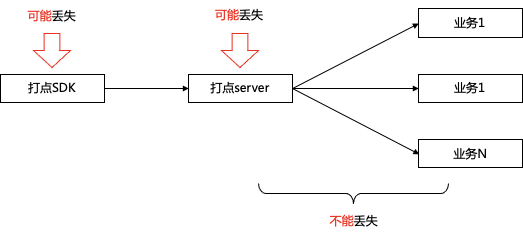
3.1.1 唯2丢失数据理论
端:由于移动端的客观环境影响,如白屏、闪退、无法常驻进程、启动周期不确定等因素,导致客户端消息会存在一定概率丢失
接入层:由于服务器不可避免的存在故障(服务重启、服务器故障)的可能性,也存在一定的数据丢失概率
计算层:接入点之后,基于流式框架,建设需要严格意义的保证数据不重不丢。
3.1.2 日志中台架构优化方向
数据接入层面:
先持久化数据,后业务处理的原则
降低逻辑复杂度
下游转发层面:
实时流类:严格意义不丢失
高时效类:保证数据时效,允许可能存在的部分丢失
资源隔离:将不同业务的部署进行物理隔离,避免不同业务相互影响
区分优先级:按照业务对不同数据诉求,区分不同类型
3.2 架构拆解
基于日志中台现状分析,结合日志打点服务的唯2理论,我们针对日志中台对现有架构进行问题拆解和架构重构。
3.2.1 打点server服务拆解(优化接入层数据丢失)
基于以上不重不丢的理论,日志接入层进行了如下几个方面的建设,尽可能做到数据不重不丢。
日志优先持久化:尽可能降低接入点因服务器故障等原因导致的数据丢失问题;
巨型服务拆解:接入点应该秉承简单、轻量的思路建设,避免过多业务属性导致的服务稳定性问题;
灵活&易用:在不重不丢的同时,基于业务需求特点,设计合理的流式计算架构。
Presto进程管理实现监控及自动重启
星期四, 十月 21st, 2021 | JAVA-and-J2EE, 大数据 | 没有评论
具体搭建就不说了可以参考官方文档
https://prestodb.io/docs/current/
其他查询接口也列下:
默认UI是:根据更改的端口调整
http://xxx:8080
获取集群状态 接口:
http://xxx/v1/cluster
获取NODE信息:接口:
http://xxx/v1/node
访问/v1/info/state, 直接从worker处获取worker的状态
取各节点的版本详情 获取节点信息的接口:
http://xxx/v1/service
具体监控信息如下:
› Continue reading
Elasticsearch技术使用(ES): 索引别名Aliases问题
星期四, 七月 8th, 2021 | JAVA-and-J2EE, 大数据 | 没有评论
业务问题#
业务需求是不断变化迭代的,也许我们之前写的某个业务逻辑在下个版本就变化了,我们可能需要修改原来的设计,例如数据库可能需要添加一个字段或删减一个字段,而在搜索中也会发生这件事,即使你认为现在的索引设计已经很完美了,在生产环境中,还是有可能需要做一些修改的,需要添加映射字段或者需要修改字段类型等等。
数据库中我们可以直接修改原来的表设计语句,前提是需要做好数据迁移。但是在 Elasticsearch 中就没那么简单了。尽管可以增加新的类型到索引中,或者增加新的字段到类型中,但是不能添加新的分析器或者对现有的字段做改动。如果你那么做的话,结果就是那些已经被索引的数据就不正确,搜索也不能正常工作。针对这个问题必须重新建立索引。
别名定义#
重新建立索引的问题是必须更新应用中的索引名称,索引别名就是用来解决这个问题的!
假设我们有个学生的原始索引 student_index_v1,我们给它起个别名 student_index,程序中也是用别名 student_index 进行搜索,当我们的业务需求发生改变需要修改索引的时候,我们重新创建个索引 student_index_v2,同时将别名 student_index 指向新的索引 student_index_v2,同时将 student_index_v1 的数据迁移到新的 student_index_v2,这样我们就可以做到在零停机下从旧索引切换到新索引。
索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用,而且别名不能与索引同名。
别名带给我们极大的灵活性,允许我们做下面这些:
在运行的集群中可以无缝的从一个索引切换到另一个索引。
给多个索引分组。
给索引的一个子集创建视图。
别名管理#
别名还可以映射到某个索引也可以映射到多个索引。别名还可以与筛选器关联,筛选器将在搜索和路由值时自动应用,别名不能与索引同名。
Elasticsearch 中有两种方式管理别名: _alias 用于单个操作, _aliases 用于执行多个原子级操作。
› Continue reading
Lambda架构和Kappa架构之常用的大数据处理架构
星期四, 六月 3rd, 2021 | 大数据 | 没有评论
首先我们来看一个典型的互联网大数据平台的架构,如下图所示:
111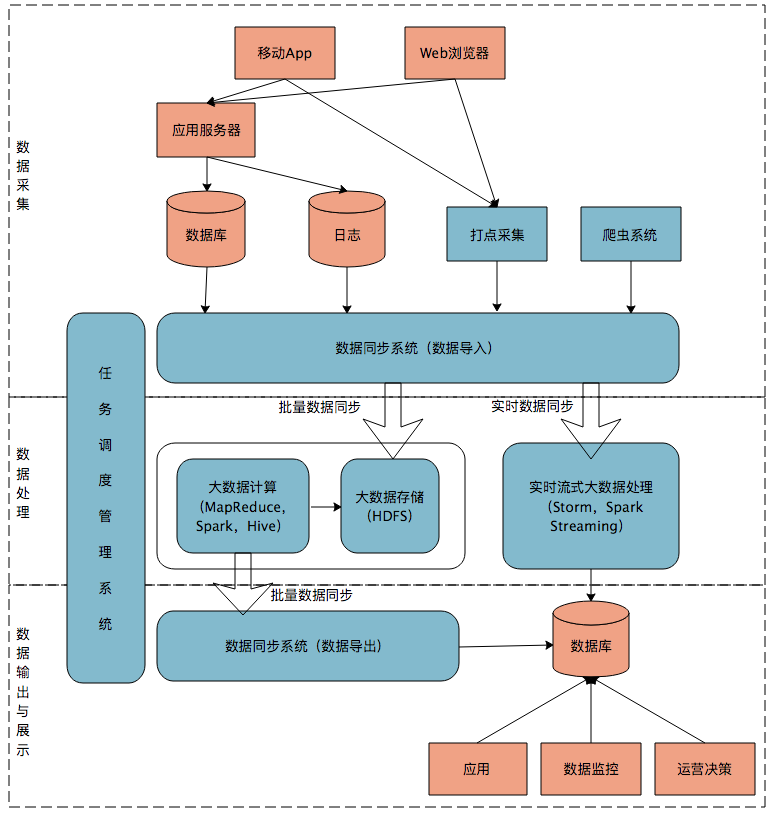
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS。
MapReduce、Hive、Spark 等进行的计算处理被称作是离线计算,HDFS 存储的数据被称为离线数据。在大数据系统上进行的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用 Storm、Spark Steaming 等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
数据输出与展示
大数据计算产生的数据还是写入到 HDFS 中,但应用程序不可能到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用 Sqoop 之类的系统导出到数据库。
大数据相关的资料信息整理篇
星期一, 四月 13th, 2020 | 大数据 | 没有评论
1.大数据相关的资料信息 需要了解和掌握的东西记录下
1.大数据技术知识
第一章:基础组件篇
分布式协调系统:ZooKeeper
大数据基础平台:Hadoop
第二章:数据采集篇
分布式日志采集系统:Flume、Canal
分布式导入数据系统:Sqoop
第三章:数据存储篇
分布式数据仓库:Hive
分布式列式数据库:HBase
分布式消息系统:Kafka
分布式列式存储系统:Kudu
第四章:数据处理篇
快速通用的分布式计算引擎:Spark
新一代的分布式计算引擎:Flink
第五章:调度篇
分布式调度系统:Azkaban
第六章:OLAP篇
分布式内存实时分析系统:Druid
实时多维分析系统:Kylin
azkaban-web-server 邮件配置遭遇Connecting to SMTP server failed
星期三, 六月 27th, 2018 | Database, JAVA-and-J2EE, 大数据 | 2 Comments
azkaban-web-server 邮件配置遭遇Connecting to SMTP server failed
0.先说下使用的版本azkaban-web-server-3.45.0-10使用jdk1.8.151编译
1.启用azkaban的邮件配置在 azkaban.properties中定义发送邮箱
mail.sender=xx@qq.com mail.host=smtp.exmail.qq.com mail.user=xx@qq.com mail.port=465 mail.password=xxxxxx #[email protected] #[email protected] mail.tls=true |
2.配置job文件里配置接收邮箱地址
#file.job type=command command=sh /usr/local/bg/files/test.sh working.dir=/usr/local/bg/files/job/working notify.emails=xx@qq.com failure.emails=xx@qq.com success.emails=xx@qq.com |
3.遭遇错误如下
ERROR [EmailMessage] [Azkaban] Connecting to SMTP server failed, attempt: 0 javax.mail.MessagingException: Exception reading response; nested exception is: java.net.SocketTimeoutException: Read timed out at com.sun.mail.smtp.SMTPTransport.readServerResponse(SMTPTransport.java:2210) at com.sun.mail.smtp.SMTPTransport.openServer(SMTPTransport.java:1950) at com.sun.mail.smtp.SMTPTransport.protocolConnect(SMTPTransport.java:642) at javax.mail.Service.connect(Service.java:295) at azkaban.utils.EmailMessage.connectToSMTPServer(EmailMessage.java:226) at azkaban.utils.EmailMessage.retryConnectToSMTPServer(EmailMessage.java:236) at azkaban.utils.EmailMessage.sendEmail(EmailMessage.java:219) at azkaban.utils.Emailer.sendSuccessEmail(Emailer.java:231) |
4.解决方式需要修改源码并重新编译之 重新编译azkaban.utils.EmailMessage即可,
› Continue reading
centos7 里面修改hostname的方式
星期三, 三月 21st, 2018 | linux, 大数据 | 没有评论
在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(pretty)。
“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。
“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。
静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。
centos7 里面修改hostname的方式有所改变,修改/etc/hosts和/etc/sysconfig/network两个文件已经不能生效。使用的新命令是:
默认 set-hostname 同时修改三个值,想只修改一个加 -static 对应的参数
shell> hostnamectl set-hostname centos7 shell> su shell> hostname centos7 |
centos7之前的版本请用此方法:
shell> vi /etc/sysconfig/network # Created by anaconda NETWORKING=yes HOSTNAME=centos6 :wq #保存并退出 |
局域网A/B主机直接通过hostname访问主机B:
#A主机设置 shell> vi /etc/sysconfig/network GATEWAY=192.168.1.100 #当前主机内网ip :wq #保存并退出 #A/B主机设置 shell> vi /etc/hosts 192.168.1.100 hostname :wq #保存并退出 |
Elasticsearch 启动报错参数配置处理 参数配置
星期五, 一月 26th, 2018 | 大数据 | 3 Comments
1.elasticsearch-6.1.2的具体就不介绍了,详情可以去看Elasticsearch guide
2.为了主机可以访问虚拟机里的ES 开启外部访问
vi config/elasticsearch.yml network.host: 0.0.0.0 #打开此注释,正式环境根据情况指定IP |
3.启动elasticsearch报如下错误
./bin/elasticsearch -d |
[2018-01-26T03:06:12,987][ERROR][o.e.b.Bootstrap ] [sA_Y-N7] node validation exception
[3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [3884] for user [hadoop] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
针对上述错误修改如下:
vi /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 |
vi /etc/security/limits.d/20-nproc.conf * soft nproc 4096 root soft nproc unlimited |
vi /etc/sysctl.conf vm.max_map_count=655360 |
使其生效
sysctl -p |
退出shell,重进生效,然后启动ok了
可以访问 http://192.168.1.188:9200/ 查看

Search
相关文章
热门文章
最新文章
文章分类
- ajax (10)
- algorithm-learn (3)
- Android (6)
- as (3)
- computer (86)
- Database (30)
- disucz (4)
- enterprise (1)
- erlang (2)
- flash (5)
- golang (3)
- html5 (18)
- ios (4)
- JAVA-and-J2EE (186)
- linux (144)
- mac (10)
- movie-music (11)
- pagemaker (36)
- php (50)
- spring-boot (2)
- Synology群晖 (2)
- Uncategorized (6)
- unity (1)
- webgame (15)
- wordpress (33)
- work-other (2)
- 低代码 (1)
- 体味生活 (40)
- 前端 (21)
- 大数据 (8)
- 游戏开发 (9)
- 爱上海 (19)
- 读书 (4)
- 软件 (3)